You know SQL. You understand data pipelines. But assembling a data stack from scratch — evaluating tools, debugging integrations, managing infrastructure — takes weeks you don't have. And managed platforms charge thousands per year for what should be table stakes.
Data infrastructure shouldn't be a privilege. It should be a standard.
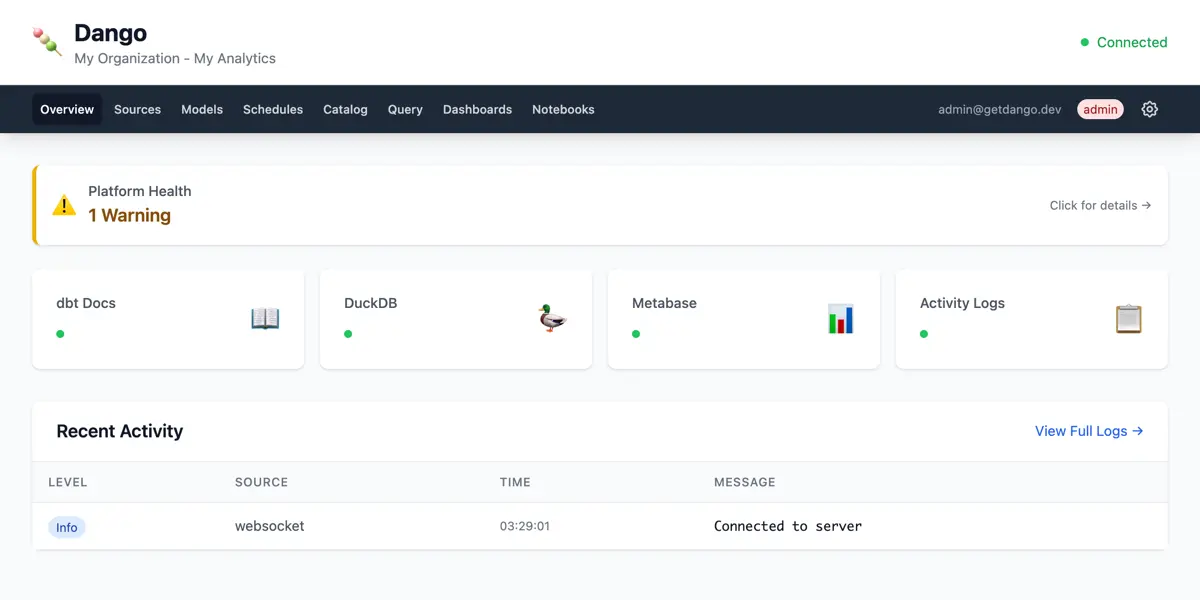
Dango gives you the full stack — ingestion, transformation, dashboards, notebooks, scheduling, and governance — integrated and production-ready. Your data, your infrastructure, zero cost.
How it works
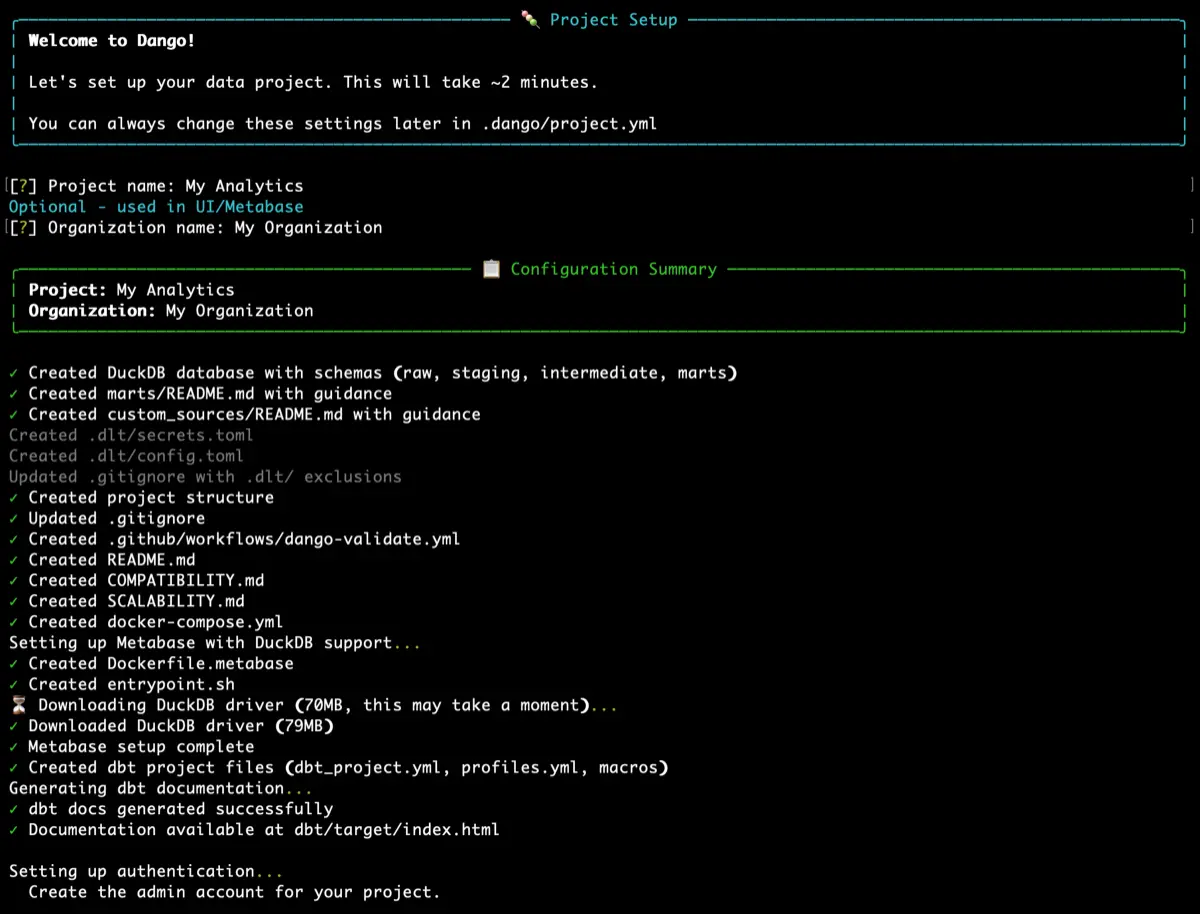
Install in seconds. Dashboards in minutes.
Four simple steps from zero to insights.
1
Install
One command. Python, Docker, and all components — DuckDB, dbt, Metabase, and the full platform — configured automatically.
2
Connect Data
Connect APIs, databases, or CSV files. Guided setup walks you through credentials and configuration. Build custom sources for any REST API.
3
Sync & Transform
Data loads, transforms, and lands in dashboards automatically. Schedule syncs hourly, daily, or on demand. Schema changes are tracked.
4
Analyze & Share
Explore data in Metabase dashboards, run SQL queries, or open Marimo notebooks for deeper analysis. Deploy to the cloud when you're ready to share with your team.
$ dango init
Why Dango?
Everything wired together, out of the box.
dlt loads your data into DuckDB. dbt transforms it automatically. Metabase dashboards update with every sync. Schedules, monitoring, and governance run without configuration. The integration work that takes weeks to do yourself? Already done.
Free, open source, always yours.
Apache 2.0 licensed. Run on your laptop or deploy to the cloud. Your data stays on your infrastructure. No vendor lock-in, no usage limits, no subscription fees. If you outgrow Dango, you take everything with you — every tool in the stack is independently portable.
Production-ready from day one.
Authentication, scheduled syncs, schema drift detection, PII flagging, webhook notifications, and cloud deployment — built in, not bolted on. Start with best practices, not tech debt.
Features
Everything you need to go from data to insights.
Data Integration
Connect APIs, databases, or CSV files with guided setup. OAuth flows for Google, Facebook, and more. Build custom sources for any REST API using dlt. Incremental loading where supported — after the first sync, only new and changed records are loaded.
Data Transformation
SQL-based transformations with dbt. Auto-generated staging models, built-in testing, and automatic documentation. Version-controlled in Git — your business logic is tracked and documented, not tribal knowledge.
Dashboards & Analysis
Metabase for interactive dashboards and SQL queries. Marimo notebooks for exploratory analysis and data science workflows. Both auto-configured and connected to your DuckDB warehouse.
Cloud Deployment
Deploy your project to a cloud server with a guided wizard. Automated provisioning on DigitalOcean, or bring any server with SSH access. Includes auto-TLS certificates, SSH hardening, firewall management, scheduled backups, and systemd auto-restart. Manage everything from your local CLI — push updates, check status, view logs, roll back.
Authentication & Security
Admin accounts, user roles, two-factor authentication, API keys, and session management. Brute-force protection and audit logging. Secure by default for both local and cloud deployments.
Scheduling & Automation
Cron-based sync schedules with automatic retries, timeout protection, and execution history. Webhook notifications to Slack or any endpoint on sync success, failure, or data staleness. File watcher auto-syncs when CSV files change.
Data Catalog & Governance
Browse tables, columns, and data profiles. View dbt model documentation, lineage, and test results in one place. Track schema drift between syncs and flag PII in your data with configurable overrides.
Monitoring & Observability
Track sync health, data freshness, and dbt test results from the web UI. Define custom metrics with trend detection and anomaly alerts. Full execution history for every sync and transformation.
The stack
Standing on the shoulders of giants.
We evaluated the open source data ecosystem and curated five tools that work well together. You skip the weeks of evaluating which tool to use for each layer of the stack and whether they integrate.
Each tool is proven in production at thousands of companies. Your skills transfer — if you outgrow Dango, you keep everything you've learned and built. Your dbt models, DuckDB data, and Metabase dashboards all work independently outside Dango.
01 Ingestion
02 Storage
03 Transformation
04 Analysis
Load
dlt
Load data from APIs, databases, and files into your warehouse.
→
Warehouse
DuckDB
Fast in-process OLAP analytics database that runs anywhere.
Each component independently portable — your work goes with you
All open source. All actively maintained. All working together.
Common questions
How is this different from just installing dbt and Metabase myself?
Dango handles the integration: dlt loads data into DuckDB, dbt transforms it, Metabase displays it — all auto-configured with scheduling, monitoring, authentication, governance, and cloud deployment included. Install once, everything works together. No configuration debugging.
Isn't this just Docker Compose with some tools?
Yes — plus the integration work, configuration, best practices, and ongoing compatibility maintenance. The hard part isn't running containers; it's making everything work together seamlessly.
What data sources can I connect?
APIs (Stripe, Google Ads, Facebook Ads, GA4, HubSpot, Salesforce, and more), databases (PostgreSQL, MySQL), CSV and Excel files, Google Sheets, and any REST API via custom sources. Dango uses dlt for ingestion — anything dlt supports, Dango supports.
Why use Dango instead of free tiers from enterprise platforms?
Dango is fully open source — you own the code, control your data, and face no upgrade pressure or artificial limits. Free tiers are designed to convert you to paid plans. What you build with Dango today works the same way at any scale, on infrastructure you control.
Can I deploy this to the cloud?
Yes. dango deploy provisions a server on DigitalOcean with automated setup, or you can bring any server with SSH access (Hetzner, AWS, Oracle Cloud, etc.). Cloud deployments include auto-TLS via Caddy, SSH hardening, scheduled backups, firewall management, and monitoring.
What's the catch? Why is it free?
Dango is a passion project built to make professional open source data tools accessible to small teams who need them most. It's Apache 2.0 licensed — free forever, no strings attached. We believe analytics infrastructure shouldn't be reserved for companies with enterprise budgets.
Is this production-ready?
Yes. Dango v1 includes authentication, scheduled syncs, schema drift detection, audit logging, and cloud deployment with auto-TLS and backups. It's designed for small teams running real workloads.
Will this scale as we grow?
DuckDB handles millions of rows. For teams of 1–10 people with typical analytics workloads, Dango is designed to be the long-term solution, not a stepping stone. The underlying tools (dlt, dbt, DuckDB, Metabase) are used in production at thousands of companies. And every component is independently portable — your dbt models, DuckDB data, and Metabase dashboards work outside Dango if you ever need to move on.
What about security?
Authentication is enabled by default. Dango includes admin accounts, user roles, two-factor authentication, session management, brute-force protection, and audit logging. Cloud deployments add SSH key-only access, auto-TLS, fail2ban, and security headers.
Can I customize or extend Dango?
Absolutely. It's open source — fork it, modify it, extend it. Build custom data sources for any REST API, write your own dbt models, create custom Metabase dashboards, or add Marimo notebooks for bespoke analysis.
What does Dango NOT do?
Dango focuses on analytics for small-to-medium teams. We're not building for petabyte-scale infrastructure, real-time streaming, or ML/AI modeling. Our roadmap evolves based on user feedback and what small teams need most.
What if Dango stops getting updates?
Every tool in the stack — dlt, dbt, DuckDB, Metabase, Marimo — is independently usable. If Dango stopped getting updates tomorrow, your dbt models still run in vanilla dbt, your data sits in a standard DuckDB file, and your Metabase dashboards work in a vanilla Metabase install. You inherit a working stack, not a dead app. The integration is the value you'd lose — the data and the work go with you.
Ready to own your data stack?
Install Dango, connect your data, and have dashboards running today. Free, open source, and yours to keep.